/ NOS OFFRES /
Data Engineering & plateforme data IA-ready
De l’architecture data lakehouse à la gouvernance des données, en passant par le data mesh et les pipelines IA-ready : Harington accompagne les DSI et CDO dans la modernisation de leur patrimoine data, avec une approche open source, souveraine et alignée sur les standards 2026.
Plus de 80 % des données sont stockées mais jamais structurées, analysées ni utilisées.
70 % des responsables IT estiment que leur architecture data freine leur capacité à innover.Source : IDC
Ces chiffres ne surprennent pas les CDO qui gèrent au quotidien des architectures hétérogènes, des pipelines fragiles et des données que l’IA ne peut pas encore consommer.
De la plateforme data à l’IA opérationnelle
La donnée est le carburant de l’IA. Une organisation qui veut déployer des agents IA, des modèles RAG ou du LLMOps ne peut le faire que si sa plateforme data est IA-ready : données de qualité, pipelines fiables, gouvernance tracée, formats ouverts et accessibilité en temps réel.
C’est pourquoi Harington gère la modernisation data et l’IA d’entreprise comme un continuum, pas comme deux projets séparés. Notre offre data engineering s’articule nativement avec nos offres IA d’entreprise et OmniA, garantissant que votre plateforme data alimente directement vos agents IA, vos pipelines LLMOps et vos modèles de gouvernance AI Act.
Le triptyque gagnant pour les CDO en 2026 :
- Data Engineering : Des pipelines robustes, des architectures lakehouse open source (Apache Iceberg, Delta Lake), une ingestion multi-sources fiabilisée
- Data Governance : Des data products, une gouvernance fédérée (DataGovOps), une data observability en continu
- Data IA-ready : Une plateforme qui alimente nativement vos use cases IA, RAG, ML et streaming temps réel
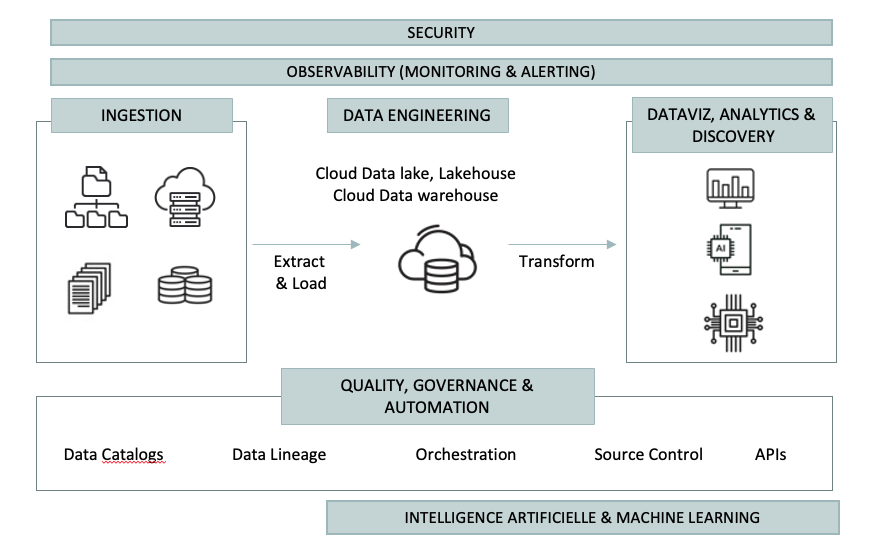
Nos solutions technologiques pour une plateforme data moderne

Data INTELLIGENCE PRACTICE MANAGER
Salah Makoudi
« Les données sont plus que jamais un game changer : elles alimentent les avancées en IA générative, transforment les modèles économiques et redéfinissent les règles de la compétitivité. Construire une architecture résiliente, garantir une gouvernance robuste et adopter une approche durable sont désormais des impératifs. »
Nos prestations de services en data / IA engineering
La donnée est au cœur de la performance. Il ne s’agit plus seulement de stocker ou traiter vos données, mais de les transformer en moteurs d’innovation grâce à des architectures modernes, des workflows IA automatisés et une gouvernance activable.
Nous vous accompagnons à chaque étape, de la définition de votre roadmap data à la mise en production de pipelines IA-ready, avec des méthodologies éprouvées et une stack open source de référence.
Conseil et stratégie Data
- Audit technique, évaluation de la maturité data (architecture, qualité, gouvernance, IA-readiness) et définition de la roadmap
- Choix d’architecture : data lakehouse (Databricks, Snowflake, Microsoft Fabric), data mesh, data fabric selon votre maturité et vos enjeux
- Identification et priorisation des cas d’usage IA/ML et intégration de l’IA dans votre stratégie data
- Gouvernance des données : conformité RGPD, AI Act, sécurité et optimisation des actifs data
- Mise en place d’un accès en libre-service (data products, catalogues de données)
- Sélection d’outils et technologies avec des alternatives open source pour limiter le vendor lock-in
Gestion de projet Data
- Pilotage de projets data complexes avec des méthodologies Agile / DataOps
- Coordination des équipes métier et IT pour aligner besoins stratégiques et opérationnels
- Conception et déploiement de solutions (POC, MVP) pour tester rapidement les cas d’usage
- Mise à disposition de compétences expertes : architectes data, data engineers, experts DataOps, data product owners, PO et program managers
- Change management pour garantir l’adoption des outils et processus data
Architecture et mise en œuvre
- Conception d’architectures modernes (data lakehouse, data mesh, data fabric, data product) pour un accès structuré, évolutif et IA-ready
- Déploiement sur Databricks (Delta Lake, Unity Catalog), Snowflake (Snowpark, Iceberg), Microsoft Fabric ou stack open source (Apache Iceberg, dbt, Airflow)
- Virtualisation et migration des systèmes legacy vers des plateformes cloud sécurisées
- Optimisation des performances des entrepôts de données et des pipelines d’ingestion
- Architecture médaillon (Bronze / Silver / Gold) pour structurer la qualité des données par couche
Solutions data et sécurité
- Mise en œuvre de MLOps et DataOps pour industrialiser vos pipelines et workflows IA
- Automatisation des processus CI/CD data et intégration des tests de performance et de sécurité
- Sécurisation des données en transit et en exploitation, conformité RGPD et ISO 27001
- Paramétrage et intégration des outils de data lineage, data catalogs et monitoring avancé
- Data observability : détection proactive des anomalies, dérives de qualité et incidents pipeline (Monte Carlo, Soda, Great Expectations)
Notre expertise en Data Engineering
Conception et orchestration des pipelines de données
Mettez en œuvre des pipelines robustes, scalables et auto-adaptatifs avec des outils comme Apache Airflow, PySpark, dbt (data build tool) et Talend. Notre approche privilégie les données en tant que produit (data products) : chaque pipeline produit un jeu de données versionnés, documentés et consommables en libre-service par les équipes métier.
Stack de référence : Apache Airflow, Prefect, Dagster, dbt Core, PySpark, Apache NiFi.
Architectures lakehouse open source : Apache Iceberg
Le débat Data Lake vs Data Warehouse est dépassé au profit d’une architecture de data lakehouse, qui offre la flexibilité du datalake avec les performances analytiques de l’entrepôt.
Apache Iceberg s’est imposé comme le format de table ouvert de référence : transactions ACID sur le stockage objet, time travel, partition pruning, évolution du schéma sans migration ; et surtout il permet une portabilité totale entre Databricks, Snowflake, Spark et les moteurs open source. Nous accompagnons les DSI dans l’adoption d’Iceberg pour sortir des formats propriétaires et construire une plateforme data réellement ouverte.
Formats ouverts maîtrisés : Apache Iceberg, Delta Lake, Apache Hudi.
Intégration de données multi-sources
Centralisez et connectez vos données issues de sources hétérogènes (IoT, APIs, bases transactionnelles, SaaS, streaming) avec des technologies telles que AWS Glue, Fivetran, Airbyte, Apache Kafka, Apache Flink, Apache NiFi.
Notre expertise couvre le batch (ELT/ETL classique) et le streaming temps réel (event-driven, Kafka, Flink); de plus en plus indissociables pour alimenter des agents IA qui ont besoin de contexte en temps réel.
Databricks, notre plateforme de référence
En tant que partenaire Databricks Consulting & System Integrator, nous accompagnons les CDO sur l’ensemble du cycle :
- Architecture Lakehouse sur Databricks (Delta Lake, Unity Catalog, MLflow)
- Migration depuis Hadoop, Teradata ou architectures legacy vers Databricks
- Data engineering et transformation avec Databricks Workflows et dbt
- Feature store, ML et LLMOps natifs sur Databricks
- Gouvernance unifiée via Unity Catalog (data lineage, access control, data sharing)
Snowflake et Microsoft Fabric
Pour les organisations dont la priorité est le SQL analytique haute concurrence et la gouvernance partagée inter-entités, Snowflake reste une référence avec ses Virtual Warehouses, Snowpark et le support natif d’Apache Iceberg. Pour les environnements fortement intégrés à l’écosystème Microsoft, Microsoft Fabric est le choix de la continuité Azure → Power BI → OneLake avec une expérience unified DataOps.
Notre expertise en DataOps
Automatisation des workflows data
Déployez des pipelines CI/CD data avec des outils comme GitHub Actions, Argo Workflows et les orchestrateurs natifs (Databricks Workflows, Airflow, Prefect). Notre approche DataGovOps intègre la gouvernance directement dans les pipelines : data contracts, tests de qualité automatisés, alertes de dérive et audit trail sans intervention manuelle.
Data observability, la qualité en continu
Au-delà du monitoring, la data observability permet de détecter proactivement les anomalies de données avant qu’elles n’impactent les décisions métier ou les modèles IA. Nous déployons des solutions de data observability (Monte Carlo, Soda Core, Great Expectations) intégrées à vos pipelines pour garantir la fraîcheur, l’exactitude et la complétude des données à chaque étape.
Collaboration agile entre équipes data et métier
Des plateformes de data product management (DataHub, Collibra, Atlan) permettent un meilleur alignement entre les équipes et une adoption durable.
Notre expertise en Business Intelligence
Conseil BI
- Cadrage selon vos cas d’usage.
- Intégration de data mesh et data fabric pour une gestion décentralisée et flexible des données.
- Accompagnement dans le choix des outils de datavisualisation selon vos enjeux (gouvernance, libre-service, IA générative).
Solutions BI
- Déploiement des solutions (Power BI, Qlik, Tableau, MicroStrategy) intégrant des capacités d’IA générative pour des analyses prédictives et la génération automatique de rapports.
- Automatisation des flux de reporting avec des connecteurs temps réel et des capacités d’analyse en streaming.
Architecture BI moderne
- Conception et mise en œuvre d’architectures modernes (data lakehouse, data mesh) offrant flexibilité et scalabilité.
- Intégration des données multi-sources dans des environnements cloud-natifs comme Snowflake, Amazon Redshift, Google BigQuery et Microsoft Fabric.
- Transition de l’approche ETL vers l’ELT avec dbt pour des transformations versionnées, testées et documentées.
Notre expertise en gouvernance et qualité des données
Conseil gouvernance
- Audit des processus (ingestion, exploitation, partage, stockage),
- Cartographie dynamique des actifs data incluant les flux en temps réel,
- Alignement des référentiels existants avec des architectures modernes (data lakehouse, data mesh),
- Définition claire des rôles et responsabilités.
Notre approche DataGovOps, la gouvernance traitée comme du code, permet d’automatiser les contrôles de conformité, les tests de qualité et l’audit trail directement dans les pipelines, sans couche de gouvernance manuelle.
Solutions de gouvernance
- POC axé sur l’automatisation, cadrage flexibilité et adaptabilité
- Catégorisation des métadonnées, déploiement de data catalogs (DataHub, Collibra, Atlan, Apache Atlas)
- Data lineage de bout en bout cloud et on-premise
- Choix d’outils DQM et management des données de références
- Mise en œuvre Informatica, Talend, Ataccama, Reltio, Collibra, Precisely
Data products, la gouvernance centrée utilisateur
Le modèle data mesh repose sur une idée centrale : les données doivent être traitées comme des produits : documentés, versionnés, testés, avec des SLA de qualité et des propriétaires identifiés.
Nous accompagnons les CDO dans la mise en place d’une organisation data product : définition des domaines, création des équipes product data, outillage (data catalogs, data contracts) et adoption progressive par les équipes métier.
Mise à l’échelle et conformité
- Rôles et accès définis, monitoring prédictif, sécurité avancée (masking, chiffrement)
- Conformité réglementaire automatisée intégrant IA éthique et protection des données
- Conformité RGPD + AI Act : Les données d’entraînement de vos modèles IA doivent répondre aux mêmes exigences de traçabilité et de qualité que vos données analytiques
Notre expertise en Intelligence Artificielle appliquée à la data
Conseil IA & data
Audit des cas d’usage IA, opportunités d’automatisation, analyse des enjeux éthiques, évaluation de l’IA-readiness de votre infrastructure data, roadmap IA, accompagnement dans le choix des technologies (LLM, RAG, fine-tuning, SLM).
La question de l’IA-readiness est devenue centrale : Vos données sont-elles en état d’alimenter un modèle RAG ? Vos pipelines peuvent-ils fournir un contexte temps réel à un agent IA ? Votre gouvernance peut-elle prouver la conformité AI Act des données d’entraînement ?
Mise en œuvre IA sur la plateforme data
- POC/MVP, développement de modèles IA (ML, deep learning, NLP, LLMs)
- Intégration de l’IA générative et des architectures RAG (vectorisation, bases vectorielles, retrieval contextuel)
- Plateformes MLOps et LLMOps sur Databricks (MLflow, Feature Store) ou stack open source
- Solutions d’IA explicable (XAI), IA embarquée, vector stores (Weaviate, Qdrant, pgvector)
- Lien natif avec notre plateforme OmniA pour l’orchestration d’agents IA alimentés par vos données
Stack IA : TensorFlow, PyTorch, Keras, OpenAI, Amazon SageMaker, Azure Machine Learning, Hugging Face, Pinecone, Databricks MLflow.
Mise à l’échelle et conformité AI Act
Déploiement et monitoring des modèles IA en production, gouvernance IA, gestion de la qualité et des biais des données d’entraînement, conformité au AI Act européen (Registre des systèmes, DPIA IA, auditabilité des données sources).
Stack technologique et référentiels
STACK TECHNOLOGIQUE ET RÉFÉRENTIELS

Data Engineering & Pipelines
Apache Spark (PySpark), dbt (data build tool), Apache Airflow, Prefect, Dagster, Apache NiFi, Fivetran, Airbyte, AWS Glue, Talend

Formats ouverts & Lakehouse
Apache Iceberg, Delta Lake, Apache Hudi, Parquet, ORC Sur stockage objet (S3, Azure ADLS, GCS)

Plateforme data
Databricks ★ (partenaire), Snowflake, Microsoft Fabric, Google BigQuery, Amazon Redshift, Apache Hive
Streaming temps réel
Apache Kafka, Apache Flink, Confluent, Amazon Kinesis, Azure Event Hubs

Business Intelligence
Power BI, Tableau, Qlik, MicroStrategy, Looker
Avec capacités IA générative intégrées

Gouvernance & qualité
Collibra, DataHub, Atlan, Apache Atlas, Informatica, Ataccama, Talend DQM, Great Expectations, Soda Core, Monte Carlo

MLOps / LLMOps
MLflow, Databricks ML, Amazon SageMaker, Azure ML, Kubeflow, Langfuse

Cloud & infrastructure
AWS, Microsoft Azure, Google Cloud, Databricks sur cloud privé/hybride, OVHcloud (souverain)
Questions fréquentes
Data Engineering
Ces trois architectures adressent des problèmes différents. Le data lakehouse (Databricks, Snowflake, open source Iceberg) résout le problème de performance et de coût : il unifie data lake et data warehouse sur un format ouvert. Le data mesh résout le problème organisationnel : il décentralise la propriété des données par domaine métier, sous forme de data products, avec une gouvernance fédérée. Le data fabric résout le problème d’intégration : il crée une couche d’abstraction qui connecte des sources de données hétérogènes sans les centraliser. La plupart des organisations démarrent par le lakehouse (fondation technique), puis introduisent progressivement les concepts de data products et de gouvernance fédérée (data mesh), et utilisent le data fabric pour résoudre les problèmes d’intégration multi-cloud ou multi-systèmes.
Apache Iceberg est un format de table open source neutre (Apache Software Foundation) qui permet des transactions ACID, le time travel, la partition pruning et l’évolution du schéma sur n’importe quel moteur de requête (Spark, Flink, Dremio, Trino, Snowflake, Databricks). Son avantage par rapport aux formats propriétaires est la portabilité : vos données ne sont pas liées à une plateforme spécifique. En 2026, les principaux fournisseurs (Databricks, Snowflake, Microsoft Fabric) supportent tous Iceberg, ce qui en fait LE standard pour les organisations qui veulent éviter le vendor lock-in. Delta Lake (Databricks) reste pertinent dans les environnements 100 % Databricks. Pour les organisations multi-cloud ou cherchant la neutralité, Iceberg est le choix recommandé.
Une plateforme data IA-ready coche cinq critères : données de qualité maîtrisée (data observability, tests automatisés), pipelines temps réel capables d’alimenter des agents IA avec des éléments de contexte actuels, formats ouverts permettant l’accès vectoriel (RAG, embeddings), gouvernance tracée des données d’entraînement (exigence AI Act), et architecture découplée permettant de connecter les moteurs IA sans réécrire les pipelines. Harington réalise un audit IA-readiness de votre plateforme data et produit une feuille de route priorisée selon vos cas d’usage IA prioritaires.
Le choix dépend de votre contexte existant et de vos priorités. Databricks est recommandé si vous avez des besoins forts en data engineering, ML/AI et que vous valorisez l’open source (Delta Lake, MLflow, Unity Catalog) : c’est la plateforme la plus avancée pour les use cases IA. Snowflake est recommandé si votre priorité est le SQL analytique haute concurrence pour des équipes BI, avec une gouvernance partagée inter-entités et un faible overhead opérationnel. Microsoft Fabric est recommandé si votre organisation est fortement intégrée à l’écosystème Microsoft (Azure, Power BI, Teams) et souhaite un déploiement rapide. Ces plateformes ne sont pas exclusives : de nombreuses organisations utilisent Databricks pour l’engineering/ML et Snowflake pour le serving BI.
La gouvernance des données conforme au RGPD et à l’AI Act repose sur la traçabilité (data lineage de bout en bout, qui a accédé à quelles données, quand et pourquoi), la qualité (tests automatisés, monitoring de dérive, data contracts entre producteurs et consommateurs) et la souveraineté (localisation des données sur le territoire de l’UE, chiffrement, pseudonymisation des données personnelles). Pour l’AI Act, les données d’entraînement des modèles doivent être documentées (provenance, biais identifiés, transformations appliquées) et auditables. Harington déploie ces pratiques de DataGovOps directement dans vos pipelines.
Vous avez besoin de renfort dans vos équipes ou d’un devis pour un nouveau projet Data ?
Nous vous proposons des prestations en assistance technique, en régie forfaitisée ou au forfait avec des engagements forts en termes de délais et de budget.
En savoir plus

Harington est partenaire Databricks (Consulting & System Integrator) à Paris et renforce son accompagnement Data Lakehouse, de l’architecture à l’exploitation à l’échelle.

Découvrez comment le Data Lakehouse transforme la gestion des données en 2025 : unification, performance, IA et réduction des coûts. L’architecture qui révolutionne l’analytique d’entreprise.

Talend et l’architecture Data Fabric permettent aux DSI d’assurer une intégration cloud-native flexible et sécurisée. En tant que solution multi-cloud, Talend optimise la gestion des données multi-sources, garantit la qualité et simplifie la gouvernance pour une entreprise data-driven.